
Data Lake and Data Warehouse
Transforming Data into Strategic Assets


Benefits

Enhanced Data Accessibility

Improved Business Efficiency

Cost Savings

Advanced Analytics and Data Science

Real-Time Insights

Enhanced Customer Personalization

Enhanced Decision-Making

Scalable Storage and Processing

Data Governance, Compliance & Security

Support for IoT and Big Data
Features

Data Ingestion

Data Storage
Data Processing and Transformation

Data Cataloguing

Metadata Management

Data Visualization and Insights

Monitoring and Performance Optimization
AI/ML Integration

Scalability and Flexibility

Data Backup and Recovery
Data Flow
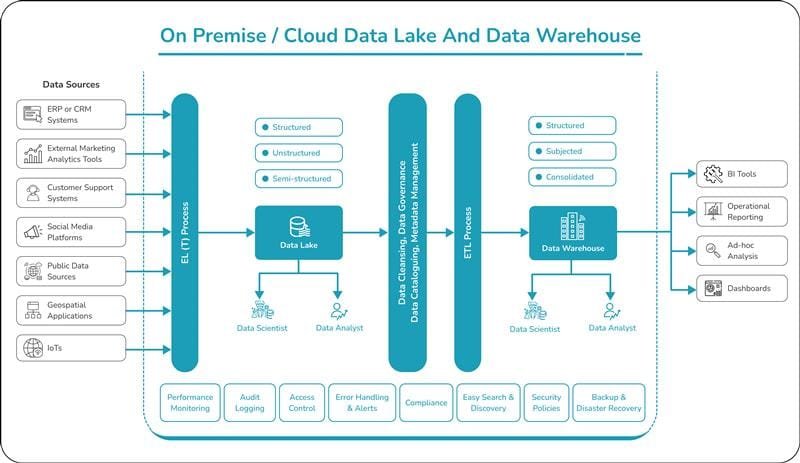
Data Ingestion
Ingests data from various sources such as ERP/CRM systems, marketing tools, IoT devices, and public data into the data lake through an EL(T) process (data pipelines), supporting structured, semi-structured, and unstructured formats.
Data Lake
The data lake serves as a centralized repository for raw, diverse data, enabling scalable big data analytics while ensuring organization through data cleansing, governance, cataloguing, and metadata management.
Data Transformation and Migration
The ETL process extracts data from the data lake, transforming it into structured, consolidated, and subject-specific formats for business intelligence and analysis. The transformed data is then stored in the data warehouse, providing an optimized environment for querying and reporting.
Data Visualization and Analytics
Data scientists, engineers, and analysts leverage the data warehouse for operational reporting, ad-hoc analysis, and creating visual dashboards. Insights are extracted using BI tools, supporting data-driven decision-making across the organization.
Use Cases for Various Industries

Healthcare and Life Sciences
Data lakes and warehouses enable healthcare organizations to integrate patient records (EHR), clinical trials, and medical research data, driving advanced analytics for personalized treatments, predictive health outcomes, and improved operational efficiency, all while ensuring compliance with regulations such as GDPR and HIPAA.
Retail and E-Commerce
Retailers leverage data lakes to process large volumes of transactional data, customer interactions, and inventory metrics in real-time. This facilitates personalized marketing, enhances customer experience, and optimizes supply chain operations, driving profitability and customer satisfaction.


Manufacturing and Supply Chain
By integrating IoT sensor data from production lines and logistics systems, manufacturers can monitor equipment performance, predict maintenance requirements, and optimize supply chains, resulting in reduced downtime, cost savings, and enhanced productivity.
Energy and Utilities
Utilities leverage data lakes to analyze real-time IoT data from smart grids and meters, enabling energy optimization and predictive maintenance. This leads to improved resource allocation, lower operational costs, and more sustainable energy management.


Educational Institutes
Educational institutes leverage data lakes to consolidate data from student records, learning platforms, and performance analytics. This enables the creation of personalized learning paths, enhances student outcomes, and improves operational efficiency for administrators and educators.
Let Us Streamline Your Data Management, So You Can Focus on Driving
Meaningful Insights and Growth.
FAQs
Data Lake stores raw, unprocessed data in its native format, supporting all types of data (structured, semi-structured, and unstructured). It's designed for flexibility and scalability, making it ideal for big data processing, AI/ML workflows, and exploratory analytics.
Data Warehouse, on the other hand, stores structured, processed data optimized for querying and reporting. It's purpose-built for business intelligence and operational reporting.
- Scalability: Cloud options often offer better scalability with pay-as-you-go pricing.
- Latency: On-premises solutions may perform better for latency-sensitive applications.
- Compliance: On-premises systems might simplify compliance for industries with strict data sovereignty requirements.
- Cost: Cloud solutions reduce upfront infrastructure costs, while on-premises may have lower long-term costs for static workloads.

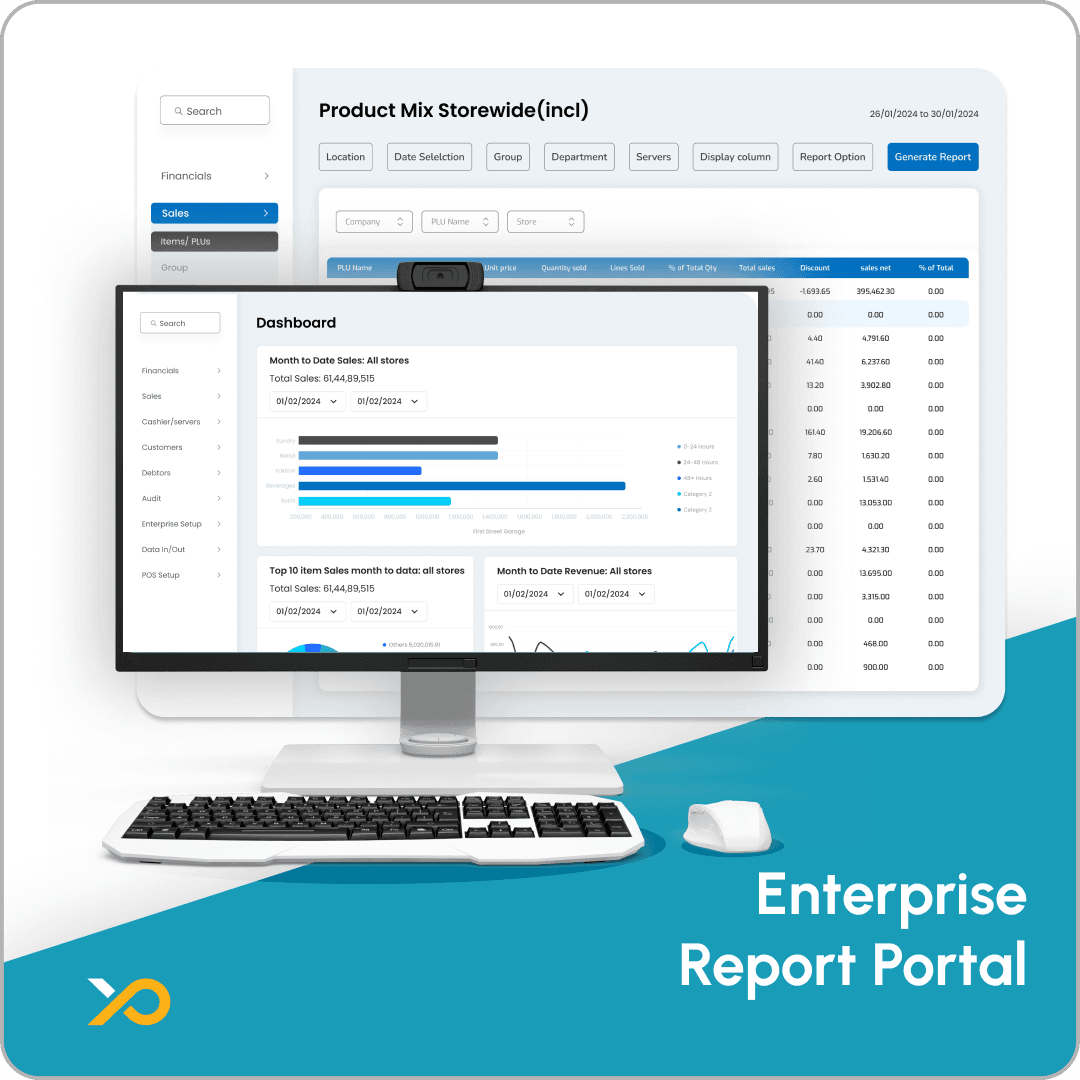






{kind=link}
{kind=link}
{kind=link}