

Future of DevOps: Trends and Techniques

Smart Cities Powered by Data

In the evolving status of data management, organizations are looking for skilled, scalable methods to process and analyze the continuously growing volumes of data constantly. At the forefront of these methods are ETLs (extracts, transforms, loads) and ELT (extract, load, transform) workflows. Both are designed to transfer data into centralized repository from different sources, they have different approaches that affect performance, scalability and suitability for different data environments.
Understanding the nuances between ETL and ELT is essential for data engineers, architects and organizations, which are aimed at creating scalable data pipelines that can keep pace with modern trade demands. This newsletter explores in detail about ETL and ELT processes, compares the best practices for their strengths and weaknesses, implementation scenarios and scalable data workflow.
What is ETL?
ETL means extract, transform, load - a traditional data integration process that has been basic in data warehousing.
⦁ Extract: Data is collected from many source systems- databases, ERP system, CRM platform, log, and more.
⦁ Transform: The data extracted is cleaned, filtered, collected, generalized and converted into a staging environment or dedicated ETL server.
⦁ Load: Processed, transformed data is loaded into target data warehouse or data mart for analysis and reporting.
Characteristics of ETL
⦁ Changes occur before loading data in the destination warehouse.
⦁ Usually, dedicated ETL is managed by tools or middleware.
⦁ The dimensional data model within the warehouse is designed for efficient queries and often follows strong schema structures such as star or snowflake schemas.
⦁ Useful in an environment where data warehouses are rigid and predetermined, and complex transformation required to applied upfront.
What is ELT?
ELT means extract, load, transform- a modern data integration process adapted to cloud and big data platform.
⦁ Extract: In ETL, data is collected from different sources systems.
⦁ Load: The data is loaded raw and untransformed in the target storage system, often a data lake or cloud data lakehouse.
⦁ Transform: The data transformation occurs inside the data warehouse or processing engine using the compute resources of target system.
Characteristics of ELT
⦁ Changes occur after the data is loaded onto the platform.
⦁ Modern cloud data avails scalability and processing power of warehouses and lakehouses (eg, snowflake, Google BigQuery, Amazon Redshift, Databricks).
⦁ Supports more flexible data ingestion- structured, semi-structured and unstructured data can be ingested with minimal upfront modeling.
⦁ The users can make various transformations on demand, supporting agile analytics and machine learning workloads.
Comparing ETL and ELT: Key Differences
|
Aspect
|
ETL (Extract, Transform, Load)
|
ELT (Extract, Load, Transform)
|
|
Processing Location
|
The data was converted into a separate ETL server or staging area before loading into the target system.
|
The raw data is loaded into the target system, and the change is done within the data warehouse or lake.
|
|
Transformation Timing
|
Before loading into the destination system.
|
After loading into the destination system.
|
|
Data Storage Type
|
Structured data warehouses with usual predetermined schemas (Schema-on-write).
|
Data supports structured, semi-structured and unstructured data in lakes or modern data warehouses (Schema-on-Read).
|
|
Scalability
|
Limited by ETL server capacity and infrastructure.
|
Highly scalable leveraging cloud compute and distributed processing.
|
|
Tooling |
Traditional ETL devices such as Informatica, Talend, SSIS.
|
Cloud-native equipment and SQL engines such as Snowflake, BigQuery, Redshift.
|
|
Schema Rigidity
|
Predefined schema and comprehensive data modeling are required.
|
The more flexible, supports the ingestion of raw data, the implemented schema applied during reading.
|
|
Use Cases
|
The regulated environment requires strict data cleaning and structured reporting.
|
Ideal for large dataset, agile analytics, machine learning and real -time processing.
|
|
Cost Efficiency
|
Cost of ETL infrastructure and data movement. |
Optimized cost by leveraging cloud provider’s compute and storage resources.
|
|
Data Processing Speed
|
Batch-oriented, usually slowed due to pre-loaded changes.
|
Rapid ingestion and processing enabled by on-demand changes.
|
|
Data Access
|
Transformed data available post-ETL process completion.
|
Raw data immediately changes as required for cases of diverse use.
|
When to Use ETL?
ETL remains relevant, especially in scenarios that require complex changes that must be tightly controlled before loading. Use ETL when:
- Working with legacy data warehouse or on-premises system requiring structured, frequently cleaned datasets.
- Data quality and stability are important, requiring rigorous verification, cleaning and transformation before the load.
- Compliance and governance determine strict data processing workflows.
- Data volumes are moderate and relatively stable.
- The organization lacks cloud infrastructure or prefers mature ETL tooling.
When to Use ELT?
The emergence of ELT is powered by cloud computing and large data processing engine, which makes it ideal:
- Data volumes are massive and come from diverse structured, semi-structured and unstructured sources.
- Data ingestion is required near real time or real time.
- Agility is a priority - data scientists and analysts can detect raw data and define transformations as required.
- The organization plans to adopt cloud-native data warehouse or lakehouse with on-demand scalability.
- Architecture requires supporting a wide range of analytics and machine learning workloads.
Architectural Considerations
ETL Architecture Overview
In ETL workflows, data is extracted from various sources systems, then passed through a dedicated transformation engine - either a centralized ETL server or cluster. After the transformation, the clean and structured data is loaded into the data warehouse.
- Often the intermediate staging areas are involved.
- ETL developers are required to maintain external complex transformations in the warehouse.
- ETL can withstand bottlenecks due to certain computing resources on the server.
- Batch processing is common due to processing time.
ELT Architecture Overview
In ELT Workflows, cloud data streams the raw data into the cloud object store or data lake, with transformation implemented by a large -scale parallel processing engine of warehouse or data lakehouse.
- The data initially lives in its raw form, supports the schema-on-read.
- The transformation script (often SQL) is implemented to leverage the elastic calculation resources of the data platform.
- Batch and streaming supports ingestion mode.
- Self-service enables analytics through flexible and dynamic query.
Benefits of ETL
- Mature and well -understood method with piles of commercial devices.
- Strong support for complex changes with tight control.
- Suitable where strict schemas and quality control are required before data consumption.
- Often small, on-premise data is better suited to the environment.
Benefits of ELT
- High scalability leveraging cloud infrastructure.
- Data reduces movement; Raw data stored centrally supports several use cases.
- Enables flexible data exploration and recurrence analysis.
- The warehouse-native intensifies deployment through simplified workflows using processing.
- AI/ML provides integration with AI/ML workflows by providing access to raw dataset.
Challenges and Limitations
ETL Challenges
- Scaling is limited by hardware and ETL server capacity.
- The setup and maintenance of staging areas increases complexity and storage costs.
- Transformation scattered in many layers can complicate troubleshooting
- Slow adaptation to change data requirements compared to ELT.
ELT Challenges
- Cloud data depends a lot on the processing power and features of the platform.
- Raw data requires mature governance to manage access and maintain data quality.
- Possible complex changes in SQL or Custom Script may require more technical expertise.
- Data privacy and compliance should be carefully managed when raw data is roughly accessible.
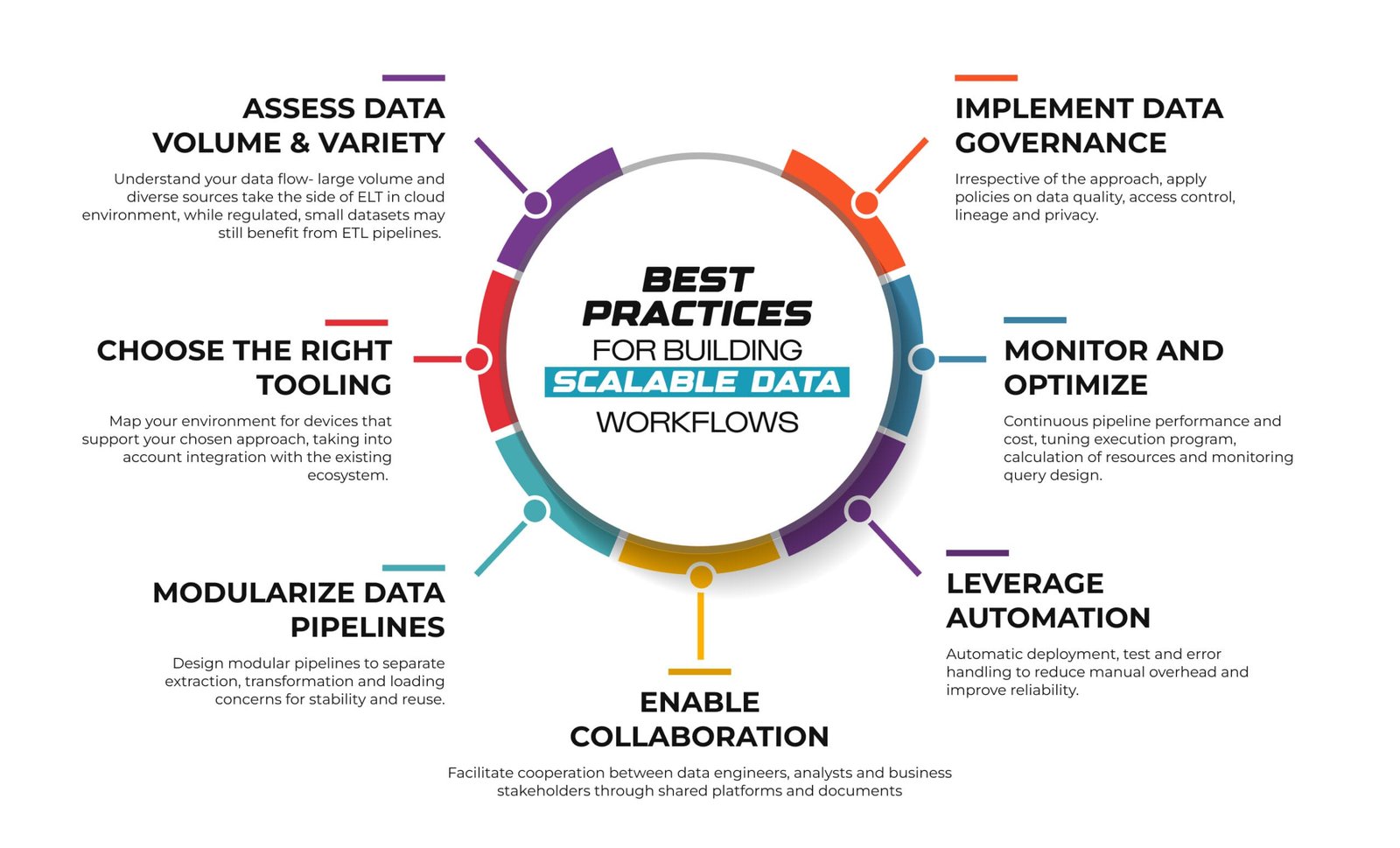
Best Practices for Building Scalable Data Workflows
- Assess Data Volume and Variety: Understand your data flow- large volume and diverse sources take the side of ELT in cloud environment, while regulated, small datasets may still benefit from ETL pipelines.
- Choose the Right Tooling: Map your environment for devices that support your chosen approach, taking into account integration with the existing ecosystem.
- Modularize Data Pipelines: Design modular pipelines to separate extraction, transformation and loading concerns for stability and reuse.
- Implement Data Governance: Irrespective of the approach, apply policies on data quality, access control, lineage and privacy.
- Monitor and Optimize: Continuous pipeline performance and cost, tuning execution program, calculation of resources and monitoring query design.
- Leverage Automation: Automatic deployment, test and error handling to reduce manual overhead and improve reliability.
- Enable Collaboration: Facilitate cooperation between data engineers, analysts and business stakeholders through shared platforms and documents
Best Practices for Building Scalable Data Workflows
Real Life Case Studies
Case Study 1: Netflix's Transition to ELT on Cloud Data Platform
Background:
Netflix manages the petabytes of data from user interactions, content metadata and device logs to customize the world's major streaming service, customizing streaming quality and personalizing material recommendations. Initially, Netflix used traditional ETL procedures for data pipelines, where the data was extracted from various sources, was converted into an orchestration layer, and then loaded into their Hadoop-based data warehouse.
Challenge:
As the data volume of Netflix increased and analytical requirements became more complex, the traditional ETL approach became a bottleneck. The transformation consumed important calculation resources and long data processing time, delaying insight. The rise of cloud platforms with elastic and scalable calculations gave an opportunity for adaptation.
Solution:
Netflix adopted an ELT approach by migrating the workflows in a highly scalable cloud data warehouse. The raw data was loaded directly into the cloud storage layer, with its elastic processing capacity with changes implemented inside the data warehouse. This re-architecture allowed Netflix to do on-demand transformation and searching analytics without transferring large datasets.
Outcomes:
⦁ Owing to the rapid data pipeline leads to scalable runtimes in -warehouse transformations.
⦁ Better agility with the ability to dynamically modify the transformation logic to suit the analytical requirements.
⦁ Cost efficiencies realized through optimized cloud compute utilization versus maintaining external ETL clusters.
⦁ Advantage to semi-structured data formats, enabling rich and more diverse data sources in analytics.
Key Takeaway:
The switch to ELT by Netflix shows how cloud-native abilities and scalable compute for big organizations leads to flexible, high-performance data workflows
Case Study 2: Capital One’s Use of ETL for Compliance and Security
Background:
Capital One, a major financial services institute, depends much more on data to explore and support regulatory reporting. Due to strict compliance rules such as GDPR and PCI-DSS controlling financial data, strict control over data quality and traceability is necessary.
Challenge:
Data architecture of Capital One requires that sensitive customer data undergoes complete cleaning, verification and masking before data storage. Their data consumers were expected to have highly reliable, consistent data for accurate reporting and risk assessment. Using ELT where raw data was previously loaded with data governance and safety concerns.
Solution:
Capital One applied a traditional ETL approach leveraging mature ETL platforms to transform the data before loading to its safe enterprise data warehouse. The ETL layer handled the aligned data with regulatory requirements to the classification, and enrichment. In addition, strong workflow orchestration ensured traceability and audits in the entire process.
Outcomes:
⦁ Controlled, ensured 100% compliance with the regulatory mandate through audio data changes.
⦁ Analysts and reporting systems distribute high-confidence datasets to improve decision making accuracy.
⦁ Maintained tight security on sensitive information during all data processing stages.
⦁ While ETL processing was resource-intensive, the approach minimized compliance risks and determination data regime.
Key Takeaway:
The dependence of Capital One on ETL underlines pre-loaded transformation in highly regulated industries and the ongoing importance of data regime where data security and belief are paramount.
Looking Forward: The Future of ETL and ELT
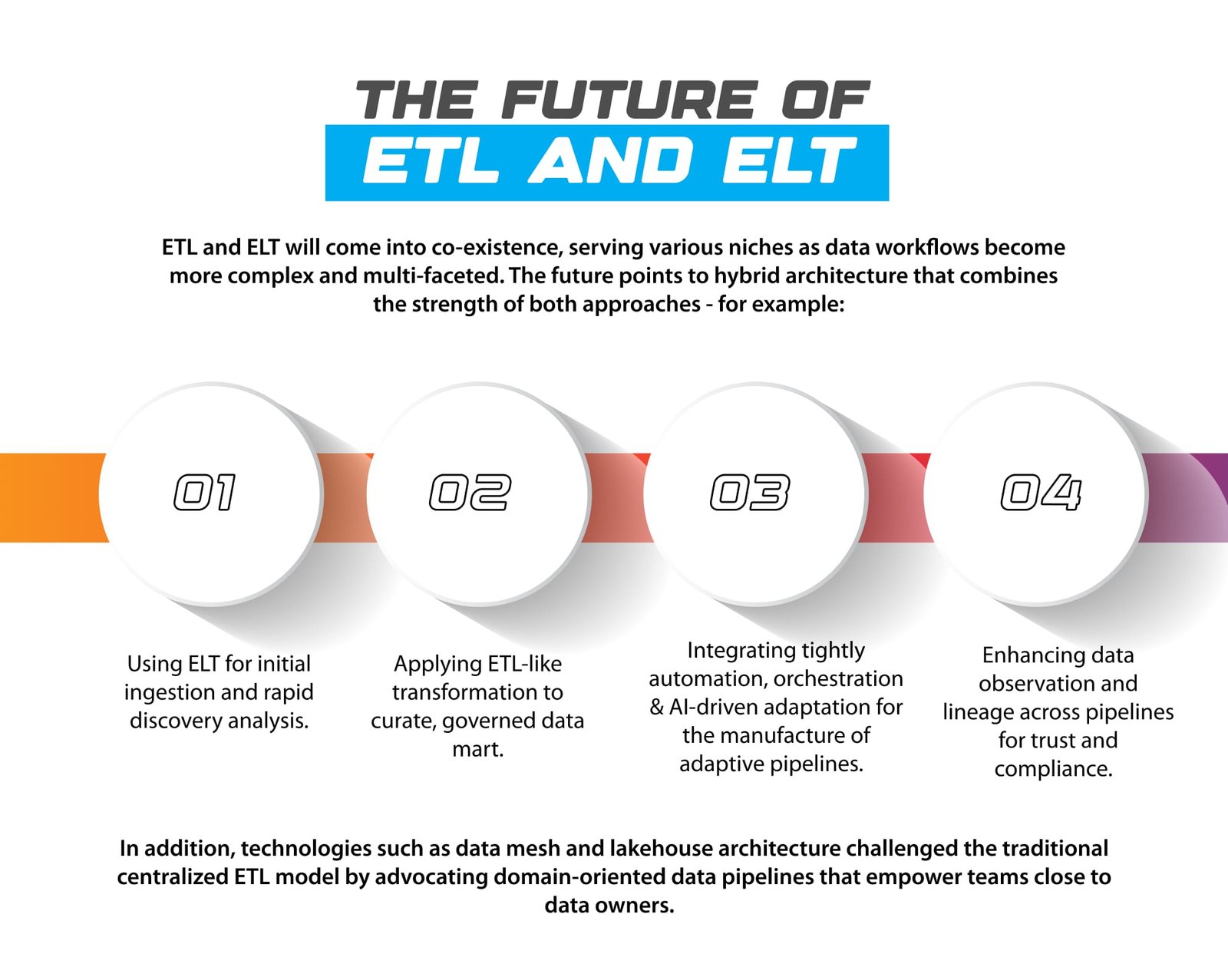
ETL and ELT will come into co-existence, serving various niches as data workflows become more complex and multi-faceted. The future points to hybrid architecture that combines the strength of both approaches - for example:
⦁ Using ELT for initial ingestion and rapid discovery analysis.
⦁ Applying ETL-like transformation to curate, governed data mart.
⦁ Integrating tightly automation, orchestration and AI-driven adaptation for the manufacture of adaptive pipelines.
⦁ Enhancing data observation and lineage across pipelines for trust and compliance.
In addition, technologies such as data mesh and lakehouse architecture challenged the traditional centralized ETL model by advocating domain-oriented data pipelines that empower teams close to data owners.
The Future of ETL and ELT
The Ending Note
Selection between ETL and ELT is less about which method is universally better and more about aligning data workflows for organizational requirements, infrastructure and business goals. Both approaches offer powerful framework for the manufacture of scalable data pipelines, each with unique benefits and trade-offs.
The ETL is invaluable for organizations with rigid, well -defined data warehousing requirements and heavy transformation outside the ETL destination system.
The modern cloud demands the ability to process large, varied datasets with flexible analytics capabilities in the modern cloud environment.
To manufacture scalable data workflows require a thoughtful strategy integrating people, process and technology. Organizations that adapt to cloud technologies, embrace automation, and foster cooperation will unlock the full capacity of their data assets-enhance better decisions, innovation and competitive advantage in a data-driven world.
Whether ETL or ELT, the future is about evolution and integration, creating data workflows that are robust, efficient, and designed for scale.
This Article is also here

{kind=link}
{kind=link}