

Top Tools for Big Data Optimization

In the current digital age, businesses generate and collect large amounts of data from different types of sources. Big data has become a backbone to make informed decision, improve operational capacity, increase customer experiences and drive innovation. However, the sheer volume, velocity and variety of big data can effectively create important challenges in action, processing and extracting actionable insights.
To leverage the correct capacity of big data, optimization, storage, processing and analysis of data workflows is important. This requires reliable, scalable and efficient large data tools to suit the specific stages of the data cycle. The optimization of big data operations ensures low cost, rapid processing, more accuracy, and better use of resources.
In this newsletter, we will explore top tools for big data optimization in various categories - date storage, processing, analytics, orchestration and monitoring. We also explore these tools to explore their capabilities, highlighting their general use cases and guidance to select the best fit for your organization's big data environment.
Understanding Big Data Optimization
Big data optimization involves increasing the efficiency and effectiveness of the entire data life cycle - from ingestion and storage to processing, analysis and reporting. The objectives include:
- Reducing processing time by maintaining or improving data quality.
- Reducing storage costs through efficient data compression and management.
- Automatic workflows for seamless integration and reducing manual intervention.
- Ensuring system scalability to handle growing data volume and user demands.
- Improve data access for analytics and AI/ML workloads.
Optimization is obtained by leveraging specialized tools designed for distributed computing, resource management, data compression, query acceleration, and more.
Categories of Big Data Optimization Tools
1. Data Storage and Management Tools
Efficient storage and management of data underlines all major data operations. Customized data storage tools ensure scalability, fault tolerance and cost-efficiency.
- Apache Hadoop HDFS: A fundamental distributed file system to store large datasets in groups designed for high throughput and fault tolerance.
- Cassandra: A highly scalable, distributed NoSQL database, designed to manage large volumes of data in the commodity server, provides high availability without a point of failure.
- Azure Data Lake: Microsoft's cloud-based scalable data is built on lake solution Azure Blob storage, designed to store vast amounts of structured and unstructured data. It integrates deeply with Azure analytics services like Azure Synapse Analytics, HDInsight, and Databricks to offer advanced big data processing and analytics capabilities.
- Amazon S3: A highly scalable cloud object storage service that offers durability, safety, and cost-effective data collection, integrated with various large data analytics services.
- Google Cloud Storage: Seamless data cycle management with durable, scalable and cost-effective object storage, ideal for big data lakes.
- Delta Lake: An open-source storage layer that provides ACID transactions, scalable metadata handling, and integrates batch and streaming data processing on data lakes.
- Apache Iceberg and Apache Hudi: Modern Table format that enables aged and optimized data layouts for better query performance.
2. Big Data Processing Frameworks
Processing large-scale datasets is a main aspect of optimization. The framework provides computing capacity distributed to parallelize workloads.
- Apache Spark: A sharp, in-memory data analytics engine that supports SQL, streaming, machine learning and graph processing.
- Apache Flink: Designed for high-throughput stream, low latency and batch data processing with advanced event-time semantics.
- Amazon SageMaker: A fully managed service that enables developers and data scientists to create, train and deploy machine learning models.
- Amazon Kinesis: A real -time data streaming platform that collects, processes and analyzes streaming data for real-time insight.
- Azure Databricks: An Apache Spark-based Analytics platform optimized for Microsoft Azure Cloud, which provides collaborative notebooks and integrated workflows for big data processing and AI.
- Presto (Trino): A distributed SQL query engine optimized for interactive analytics on large data sets from heterogenous sources.
- Dask: A flexible parallel computing library for python enables optimized computation on big data.
3. Data Warehousing and Query Optimization
These tools provide scalable SQL analytics on big data.
- Snowflake: A cloud-native data warehouse with automatic scaling, customized compression and low-oppression query performance.
- Google BigQuery: A server-free, highly scalable data warehouse with built-in machine learning and real-time analytics capabilities.
- Amazon Redshift: A fully managed, Petabyte-scale Data warehouse with automatic workload management and query optimization.
- ClickHouse: A fast, open-source column database and optimized to real-time analytics designed for OLAP applications.
- Hive: A data warehousing infrastructure built on top of Hadoop to provide data summary, query and analysis using SQL-like language.
- Azure Synapse Analytics: An integrated analytics service that combines big data and data warehousing, enables analytics on petabyte-scale data with on-demand or provisions provided resources.
4. Workflow orchestration and Automation
To optimize big data requires automation and orchestration of data pipelines to reduce manual errors and delays.
- Apache Airflow: A popular open-source workflow scheduler that defines and manage complex data pipelines with monitoring and alerting.
- Apache NiFi: Designed for data flow automation, it supports strong and scalable data routing, transformation and system mediation logic.
- Oozie: A Hadoop-native workflow scheduler manages the jobs dependent on a data processing pipeline.
- Prefect: A modern dataflow automation platform emphasizes visibility, error handling, and deployment.
- AWS Glue Workflows: An integrated orchestration service from Amazon web services that automatically carries out extract, transform and load (ETL) jobs and data workflows with dependency management and monitoring.
- Azure Synapse Pipelines: A powerful orchestration engine within Azure Synapse of Microsoft can enable scheduling, management, and data integration and automation of data integration and transformation workflows at scale.
5. Data Integration and Ingestion Tools
These efficiently optimize the process of bringing data to the system.
- Apache Kafka: A distributed event streaming platform supports real-time data ingestion and high throughput.
- Apache NiFi: A data flow automation tool that supports powerful and scalable data routing, transformation and system mediation logic with visual flow design.
- AWS Glue: A fully managed extract, transform, and load service that automatically prepares and integrates data for analytics.
- Azure Synapse: An integrated data orchestration engine within Azure synapses Analytics that manages data movement, transformation and integration workflows.
- Talend: A comprehensive data integration tool with cloud support and real time processing capabilities.
- Fivetran/Segment: Cloud-based connectors provide automatic data extraction and loaded with minimal configuration.
6. Monitoring, Profiling, and Data Quality
Continuous monitoring and data profiles are required to maintain quality and performance.
- Grafana: An open-source visualization and alerting tool that is integrated with several data sources for monitoring infrastructure and applications.
- Prometheus: System and service monitoring solutions with powerful query capabilities optimized for a cloud-native environment.
- Microsoft Purview: An integrated data governance service that helps manage, find and govern enterprise data with capabilities for data cataloging, classification, and data quality monitoring.
- AWS Glue: A fully managed extract, transform, and load (ETL) service that provides data cataloging, profiling and quality monitoring to streamline data preparation.
- Apache Atlas: Metadata governance and data lineage tools providing transparency and control over data assets.
- Datafold: A modern data quality platform for profiling, diffing and monitoring datasets.

Categories of Big Data Optimization Tools
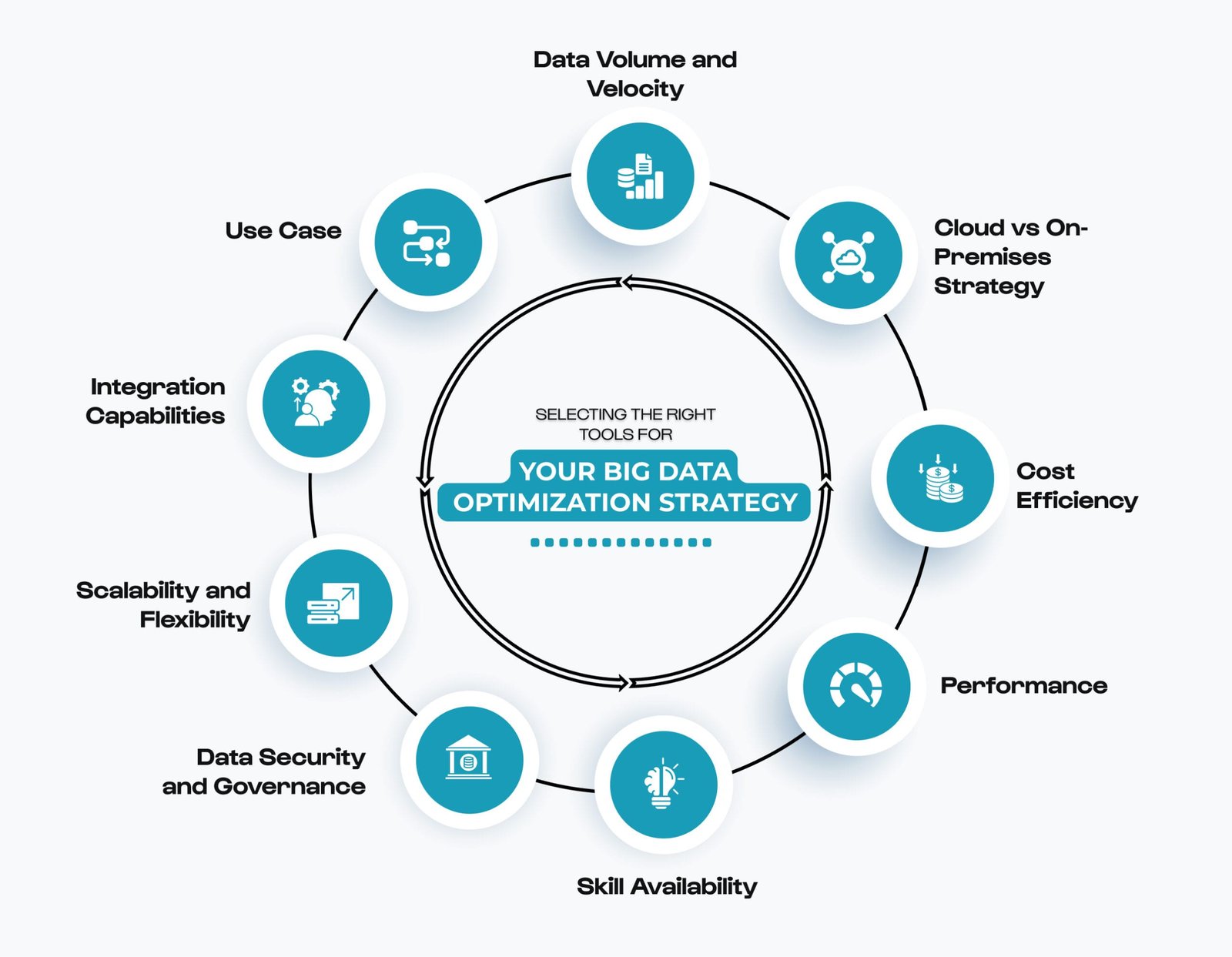
Selecting the Right Tools for Your Big Data Optimization Strategy
The factors responsible for choosing tools, need to be carefully considered:
- Data Volume and Velocity: High throughput requires streaming platforms such as kafka and rapid processing with Spark or Flink.
- Use Case: Real-time analytics, batch processing, machine learning all have different optimization requirements.
- Integration Capabilities: Tools should fit within your existing ecosystem and support interoperability.
- Scalability and Flexibility: Cloud-native equipment often provides better elasticity and cost models.
- Data Security and Governance: Compliance with regulations makes strong security facilities compulsory.
- Skill Availability: The success of adoption depends on the familiarity of teams with tools.
- Performance: Ensure that tools can handle your workload efficiently, providing data processing and analytics on time.
- Cost Efficiency: Consider both advanced and ongoing costs including infrastructure, licensing, and operational expenses.
- Cloud vs On-Premises Strategy: Evaluate whether cloud-native solutions or on-premises deployments are the best alignment with your organization's strategy, data sensitivity and regulatory requirements.
Selecting the Right Tools for Your Big Data Optimization Strategy
Industry Examples of Big Data Optimization Tools in Action
1. Netflix - Apache Spark and AWS
Netflix processes the petabytes of daily streaming data to customize content recommendations and delivery. By leveraging Apache Spark and AWS cloud resources, Netflix receives low-latency analytics and scalable machine learning training, ensuring a seamless viewer experience.
2. LinkedIn - Apache Kafka and Samza
LinkedIn handles the immense real-time data flow using Apache kafka for Apache Samza for stream processing. These tools support the monitoring of the system at a scale with targeted advertising, news feed privatization, and customized delays and fault tolerance.
3. Uber - Presto and Apache Flink
Uber uses Presto for interactive SQL analytics in vast dataset and an Apache Flink for real -time data streaming analytics, enhancing driver matching, increases surge pricing, and detects fraud with customized resource use and agility.
Best Practices for Optimizing Big Data Initiatives
- Automate and Orchestrate: Use the workflow management tool to reduce manual stages and handle complex dependencies.
- Focus on Data Quality Early: Invest in validation and cleaning to prevent wasted analytics effort on poor data.
- Leverage Cloud Elasticity: Use cloud services for dynamic calculations and storage as data grows, and analytics fluctuate.
- Implement Data Governance: Enhance trust with metadata management, lineage tracking and safety control.
- Continuously Monitor Performance: Use monitoring equipment to identify bottlenecks, optimize resource uses and ensure SLAs.
- Empower Teams: Provide training and foster support between data engineering, science, and business units.

Best Practices for Optimizing Big Data Initiatives
The Future of Big Data Optimization
This field develops rapidly with emerging trends:
- AI-Driven Automation: Intelligent optimization of data pipelines and query schemes.
- Lakehouse Architectures: Combination of flexibility of data lakes with performance of warehouses.
- Edge Analytics: Data processing close to its source to reduce latency.
- Federated Analytics: Secure analysis of data across distributed environments without centralization.
- Quantum Computing: Assurance to accelerate complex analysis of tasks beyond traditional boundaries.

The Future of Big Data Optimization
The Ending Note
Customization of big data operations is required for organizations, which are efficiently and competitively targeting to capitalize on their data assets. The ecosystem of Big Data tools is rich and diverse, customized to storage, processing, orchestration and monitoring as per various requirements.
Entrepreneurs can create scalable, strong and cost-effective big data pipelines that enable real-time insight and drive transformative consequences, understanding the capabilities of these tools and aligning them with business and technical requirements.
Staying abreast of innovation and following the best practices will make organizations capable of meeting the challenges of the growing data landscape. Embracing the right optimization tool is an important step in navigating the complex journey of success.

{kind=link}
{kind=link}