

Data Modelling: Why It’s Important for Enterprises

Turning Data into Revenue: Strategies for Monetization

Summary
In the era of digital transformation, organizations generate massive volumes of structured, semi-structured, and unstructured data. Managing, processing, and deriving insights from this data require a robust and scalable Big Data architecture. A well-designed architecture enables efficient data storage, processing, and analytics, allowing businesses to make data-driven decisions and gain a competitive advantage.
Let’s dig in!!
Types of Big Data Architecture
Big Data architecture can be broadly classified into the following types:
1.Batch Processing Architecture
- This architecture focuses on processing large datasets in batches over a scheduled period.
- It is commonly used for historical data analysis, where real-time insights are not required.
- Technologies like Hadoop and Apache Spark are widely used in batch processing.
2.Real-time Processing Architecture
- This architecture processes data in real-time or near real-time, enabling immediate insights.
- It is ideal for use cases such as fraud detection, IoT applications, and stock trading.
- Technologies like Apache Kafka, Apache Flink, and Apache Storm are used for real-time processing.
3.Lambda Architecture
- Lambda architecture combines both batch and real-time processing for accurate and fast analytics.
- It consists of two layers: a batch layer for historical data accuracy and a speed layer for real-time insights.
- Commonly implemented using Hadoop, Spark, and Kafka, Lambda architecture is suitable for scenarios requiring both real-time and historical data analysis.
4.Kappa Architecture
- Kappa architecture is a simplified version of Lambda that focuses solely on-stream processing.
- It is useful for applications where real-time insights are essential, and batch processing is unnecessary.
- Technologies like Apache Kafka and Apache Flink are commonly used to implement this architecture.
Comparison of Big Data Architectures
|
Architecture Type |
Processing Method |
Use Case Examples |
Key Technologies |
|
Batch Processing |
Batch (delayed) |
Historical analysis, ETL jobs |
Hadoop, Spark |
|
Real-time Processing |
Stream (real-time) |
IoT, fraud detection, stock trading |
Kafka, Flink, Storm |
|
Lambda Architecture |
Hybrid (Batch + Stream) |
Real-time analytics with historical accuracy |
Hadoop, Spark, Kafka |
|
Kappa Architecture |
Stream only |
Scenarios requiring real-time insights |
Kafka, Flink |
Big Data Architecture At Glance
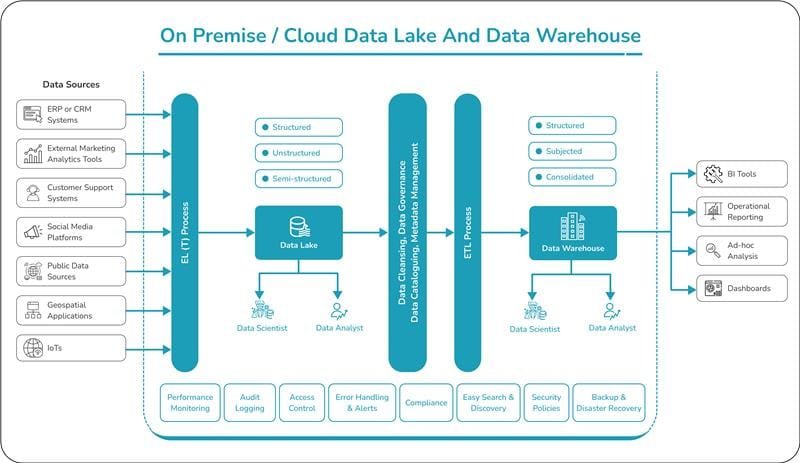
Big Data Architecture At Glance
Key Components of Big Data Architecture
A well-defined Big Data architecture comprises the following components:
|
Components |
Purpose |
|
1.Data Sources |
|
|
2.Ingestion Layer |
|
|
3.Data Lake |
|
|
4.Data Processing
|
|
|
5.Data Warehouse |
|
|
6.Analytics & BI Tools |
|
|
7.Security, Compliance, Governance |
|
The architecture ensures compliance, security, easy search, and performance monitoring while providing scalability and efficiency.
Future Proofing the Architecture & Infrastructure Setup
1.Analyzing Data Volume, Velocity, And Variety
- Data Volume: Amount of data generated
- Data Velocity: Speed of data generation
- Data Variety: Types of data (structured, unstructured, semi-structured)
|
Aspect |
Description |
Importance |
|
Volume |
Petabytes to Exabytes |
Storage planning |
|
Velocity |
Real-time to batch |
Processing capacity |
|
Variety |
Text, images, video, etc. |
Data integration |
2.Forecasting Data Growth Patterns
Predicting future data needs involves analyzing historical trends and considering potential new data sources. This helps in designing a scalable architecture that can accommodate growing data volumes and evolving business requirements.
3.Selecting The Right Tools
For Example: For Batch Processing Architecture, the matrix below can be used to decide the right tools
|
Framework |
Use Case |
Scalability |
Processing Speed |
|
Hadoop |
General |
High |
Moderate |
|
Spark |
In-memory |
Very High |
Fast |
|
Flink |
Streaming |
High |
Very Fast |
The similar technique will help deciding the right tools for any type of architecture requirements.
4.Optimizing Network Infrastructure
- Optimize network protocols
- Implement data compression
- Use parallel data transfer
5.Implementing Efficient Data Ingestion Pipelines
Efficient data ingestion pipelines are crucial for handling large volumes of data. Implement streaming technologies like Apache Kafka or Amazon Kinesis for real-time data processing. Use batch processing for historical data to balance performance and resource utilization.
6.Utilizing Cloud-Based Elastic Computing
Cloud-based elastic computing offers unparalleled flexibility for scaling compute resources. By leveraging services like AWS EC2 Auto Scaling or Azure Virtual Machine Scale Sets, organizations can:
- Automatically adjust capacity based on demand
- Optimize costs by scaling down during low-traffic periods
- Ensure high availability and performance during peak loads
|
Cloud Provider |
Elastic Computing Service |
|
AWS |
EC2 Auto Scaling |
|
Azure |
Virtual Machine Scale Sets |
|
Google Cloud |
Managed Instance Groups |
7.Implementing Container Orchestration
Container orchestration platforms like Kubernetes streamline the deployment and management of containerized applications.
8.Utilizing Predictive Analytics For Capacity Planning
|
Metric |
Importance |
Impact |
|
CPU usage |
High |
Resource allocation |
|
Storage growth |
Medium |
Expansion planning |
|
Network traffic |
High |
Bandwidth optimization |
9.Robust Logging & Monitoring System
Implementing robust logging and monitoring systems is crucial for maintaining optimal performance in big data architectures. By collecting and analyzing logs from various components, organizations can quickly identify and resolve issues, ensuring smooth operations.
10.Predictive Capacity Analysis
Predictive analytics plays a vital role in capacity planning, enabling proactive resource management. By analyzing historical data and trends, organizations can anticipate future needs and scale their infrastructure, accordingly, avoiding bottlenecks and optimizing costs.
Challenges of Big Data Architecture
1.Data Quality Management
- Managing data quality is a significant challenge due to multiple data sources contributing varying formats and levels of accuracy.
- Ensuring consistency, completeness, and accuracy requires robust data governance strategies.
2.Scalability Issues
- With exponential data growth, organizations must ensure their storage and processing systems can scale efficiently.
- Cloud-based solutions help mitigate scalability concerns but may introduce cost management challenges.
3.Real-time Processing Complexity
- Handling continuous data streams in real-time requires high computational resources and well-optimized algorithms.
- Implementing real-time analytics effectively involves choosing the right technologies and infrastructure.
4.Security & Compliance
- Protecting sensitive data from breaches and ensuring compliance with global data regulations are critical challenges.
- Strong authentication, encryption, and access control policies help safeguard data.
5.Integration Challenges
- Organizations need to integrate data from various heterogeneous sources, including legacy systems and cloud platforms.
- Ensuring smooth interoperability between different systems is crucial for a cohesive data ecosystem.
6.Cost Management
- Managing infrastructure costs, especially for cloud-based Big Data solutions, can be challenging.
- Optimizing storage, processing, and computational resources is necessary to prevent cost overruns.
Conclusion
Big Data architecture is essential for organizations to harness the power of data for analytics and decision-making. Choosing the right architecture depends on the specific use case, whether it involves batch processing, real-time processing, or a hybrid approach. The provided diagram illustrates a comprehensive architecture that integrates Data Lakes and Data Warehouses, ensuring scalability, compliance, and efficient data processing. However, organizations must address challenges such as data security, real-time processing, and cost management to successfully implement a Big Data solution.
This Article is Also here

{kind=link}
{kind=link}