

Data Explosion: The Unstoppable Surge of Data

The Future of Data Science: Important Emerging Trends

n the present-day data-driven age, the most crucial aspect of any successful enterprise is their capabilities of processing, analyzing, and reacting to data in the right way. Data pipelines are the unsung heroes behind this process. Without them, data remains a liability instead of an asset that helps organizations make better decisions and grow. Complete Guide to Engineering Excellence in Data Pipelines is prepared to help organizations save time, money and energy. I have also enclosed a link to the checklist that can be followed to achieve excellence in data pipelines.
Over 1,000 data pipelines were analyzed and the result by Datachecks was that 72% of data quality issues are not found until after they have an impact on business decisions. Furthermore, data teams waste about 40-50% of their time fixing data conflicts and quality issues instead, detracting focus from future-focused strategies. Alarmingly, 30% of data quality problems result in direct revenue loss, ranging at an average of $200,000 per incident.
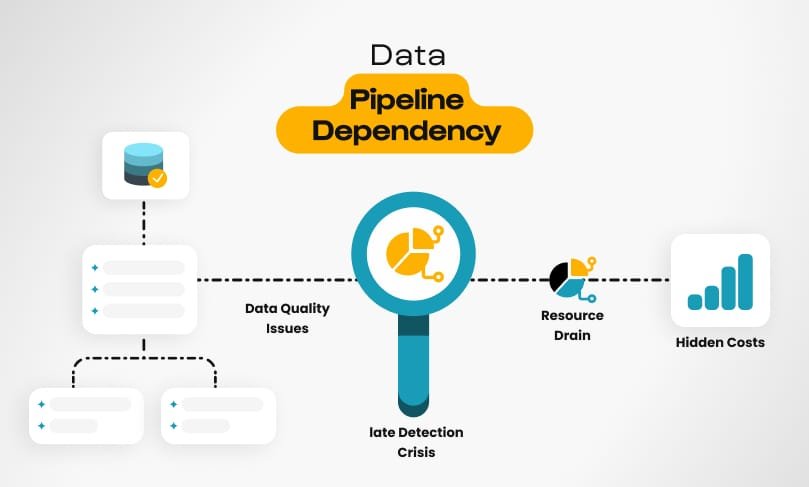
When it comes to data pipelines, achieving engineering excellence becomes inevitable to navigate through the complexities of data management. In addition, we will explore the foundational concepts, industry standards, and tools you need to know in order to create scalable, reliable, and effective data systems.
What are Data Pipelines and Why Do They Matter
Data pipelines are automated processes that allow data to flow from sources to destinations such as data warehouses or analytical tools. They include data ingestion, transformation, and loading to facilitate a smooth flow of data throughout the ecosystem.
Importance of Data Pipeline
1. Allowing Work with Real Time and Batch Processing:
Data pipelines enable organizations to react quickly to changes in business needs by supporting real-time analytics and batch processing through the integration of diverse data sources.
2. Supporting Decision Making, Analytics, and ML:
Data pipelines allow organizations to gain insight from their data, supporting analytics initiatives and training machine learning models.
3. Business Innovation and Operational Efficiency:
In a fast-paced world, companies strive to outsmart competitors through rapid innovation that makes data pipelines more efficient, and in turn, efficient data pipelines streamline workflows.
Challenges in Data Pipeline
Common pain points in data pipeline development include:
· Different types of Data sources: APIs, Flat files, unstructured data, images & videos. In addition, variable data structures are a huge obstacle to data processing.
· Scalability Issues: If not cared for, Data pipelines usually fail to cope with continuously growing data volume or impact performance significantly.
· Consistency & Quality of Data: Importing data from various sources makes it challenging for data engineers to maintain accuracy, avoid duplication, and validate information for required quality.
· Complexity of Orchestration: Making pipelines is only the beginning. It requires a massive effort by itself to manage each of them efficiently while keeping in mind the flow.
· Latency vs. Batch processing: Find the set of needs on one end are appreciative of real-time data but on the other favoring batch processing for optimal performance.
· Security & Compliance: Data is most vulnerable to risk when it is being transferred. While executing, it is important to protect the sensitive data via strong encryption, access control, and in accordance with regulations like GDPR, HIPAA, etc.
· Cost Optimization: External data collection and storage can be expensive. It is of outmost importance to navigate the resources and enable disable it at timely intervals to manage the cost.
Key Principles of Engineering Excellence in Data Pipelines
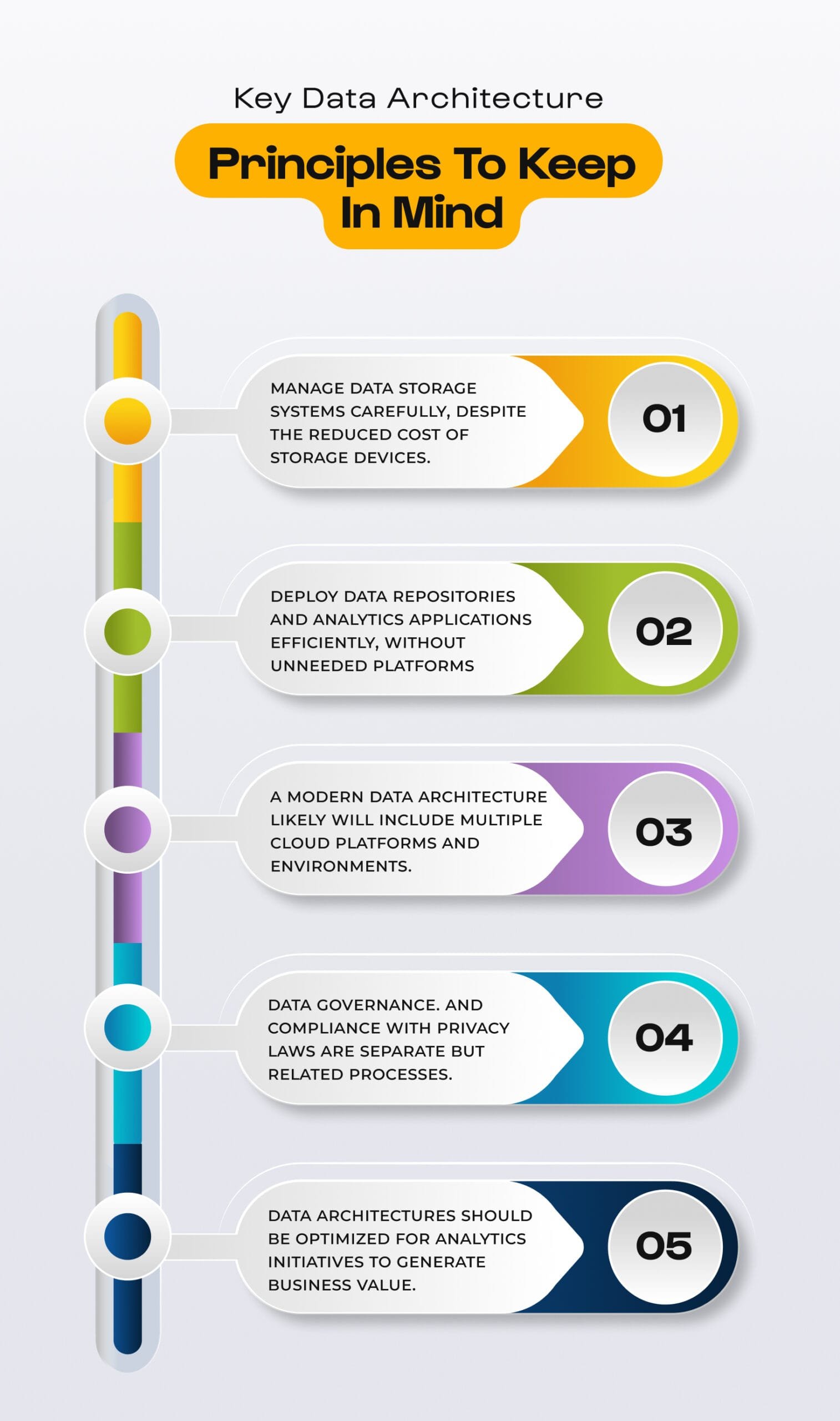
Scalability
- Scalable Data Volume & Complexity: Pipelines are designed to handle and scale with the increase in volume of Data and business complexities.
- Use Distributed & Cloud Technologies: Utilize distributed computing to enhance processing power and flexibility.
Reliability
- Data Loss Prevention: Implement checks to ensure data does not get lost while being processed.
- Error Handling & Retries: Implement detailed error handling to pinpoint the exact error and area of error. Mechanism to retry / resume from the point of failure or to isolate the point of failure and move ahead with proper logging for manual handling.
Efficiency
- Optimizing Data Processing for Speed and Cost-Effectiveness: Strive to minimize resource usage while maximizing throughput.
- Reducing Latency and Resource Consumption: Analyze bottlenecks and optimize configurations.
Maintainability & Modularity
- Writing Clean, Modular and Well-Documented Code: When it comes to code, clear code will be beneficial later for any kind of updates or troubleshooting.
- Automation of Testing and Deployment Processes: Adopt CI/CD tools to facilitate software delivery.
Security and Compliance
- Encrypt, Manage Access Control: Use security to protect the integrity and privacy of sensitive data.
- Compliance with Regulations: Ensure consistency in GDPR, HIPAA and other standards.
Key Architectural Considerations
- Batch vs. Streaming Pipelines: Choose the appropriate approach based on data needs.
- ETL vs. ELT: Understand modern trends in data transformation.
- Event-Driven & Microservices Architectures: Utilize decoupled architectures for flexibility.
- Data Governance & Security: Ensure compliance and foster data trust.
Best Practices for Building High-Performance Data Pipelines
Data Ingestion
- Choosing the Right Tools: Use platforms like Apache Kafka or AWS Kinesis for effective data ingestion.
- Handling Diverse Data Sources: Design pipelines to manage structured, semi-structured, and unstructured data.
Data Transformation
- Utilizing Frameworks: Utilize Apache Spark, Apache Beam, or dbt for efficient transformations.
- Ensuring Idempotency and Consistency: Implement practices to maintain data stability during transformation.
Data Storage
- Selecting Appropriate Storage Solutions: Consider data lakes for raw data and warehouses for structured analysis.
- Optimizing Query Performance and Cost: Balance performance and expense in storage solutions.
Monitoring and Observability
- Implementing Logging, Metrics, and Alerts: Monitor pipeline performance for proactive management.
- Using Tools: Leverage platforms like Prometheus, Grafana, or Datadog for insights.
Fault Tolerance & Recovery Mechanisms
- Idempotency, Retries, and Versioning: Develop robust recovery processes.
Tools and Technologies for Modern Data Pipelines
- Open-Source Tools: Explore options like Apache Airflow, Apache NiFi, and Luigi for flexible customization.
- Cloud-Native Solutions: Adopt AWS Glue, Google Dataflow, or Azure Data Factory for scalable, managed services.
- Streaming Platforms: Utilize Apache Kafka, Apache Flink, or Amazon Kinesis for real-time data processing.
- Orchestration Frameworks: Consider Prefect, Dagster, or Kubeflow Pipelines for orchestrating complex workflows.
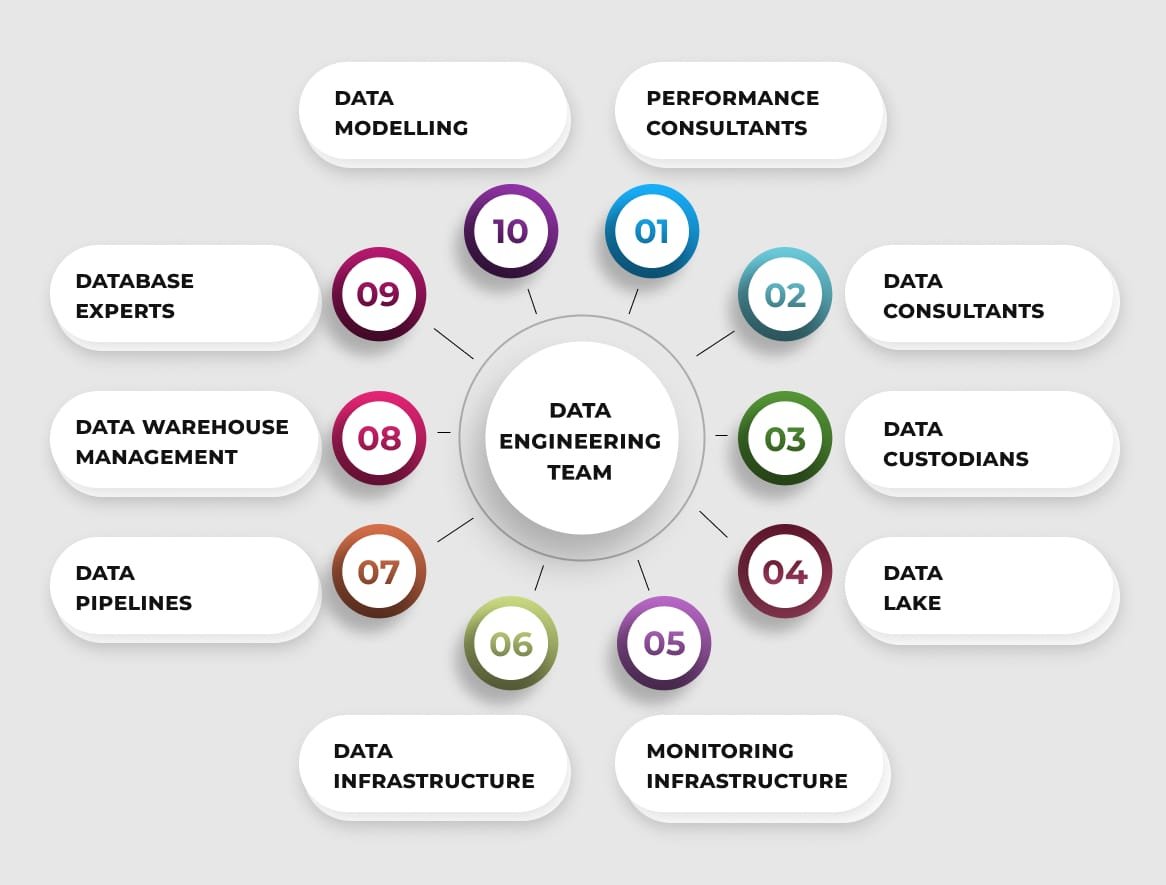
Data Engineering Team
Here’s the snapshot of the various points of expertise of the data engineering team. There’s a many to many relationship between skills and people. One person can play one or more roles and one role can be played by one or more persons. The important thing is, each role should be identified and assigned with clarity.
Case Studies of Data Pipeline for Engineering Excellence
Case Study 1: eBird's Migration to Cloud-Based Data Pipelines
Background:
The Cornell Lab of Ornithology's eBird project collects vast amounts of bird observation data from citizen scientists worldwide. This data is used to generate Spatio-Temporal Exploratory Models (STEM) that map bird migrations to provide valuable insights for both scientific research and public education.
Challenges Faced:
Initially, processing this extensive dataset required significant computational resources, which were managed on a physical cluster. This setup was not only costly but also lacked scalability which restricts the project's ability to handle increasing data volumes efficiently.
Outcome:
Transitioning to a cloud-based infrastructure, the team utilized open-source tools and cloud marketplaces to redesign their data pipeline. This shift resulted in a sixfold reduction in operational costs which enables scalable and cost-effective processing of bird migration data. The success of this migration demonstrates how cloud computing can enhance data engineering projects by offering flexibility and significant cost savings.
Key Takeaways
Scalability is Crucial:
The transition from a physical cluster to a cloud-based infrastructure highlights the importance of scalability in handling large datasets. As data volumes grow, cloud solutions provide the flexibility needed to expand processing capabilities efficiently.
Cost Efficiency Through Cloud Migration:
The significant reduction in operational costs demonstrates that cloud computing can provide substantial financial advantages for data engineering projects. Organizations should consider cloud migration as a viable strategy for cost management while enhancing performance.
Utilization of Open-Source Tools:
The successful implementation of open-source tools and cloud marketplaces shows that organizations can leverage existing resources to build effective data pipelines without the need for proprietary software, fostering innovation and collaboration.
Enhanced Data Insights:
By effectively processing and analyzing bird migration data, the eBird project exemplifies how improved data pipeline efficiency can lead to valuable insights in scientific research and public education.
Case Study 2: EOS's METL: Modernizing ETL Pipelines with Dynamic Mapping
Background:
EOS, part of the Otto Group—Europe's second-largest e-commerce provider—manages data from over 80 microservices. Integrating this diverse data into a cohesive system is crucial for their data warehouse and machine learning platforms.
Challenges Faced:
The primary challenge was the complexity of mapping varied data sources to a Canonical Data Model (CDM). Traditional ETL processes struggled with the dynamic nature of microservices which leads to difficulties in maintaining accurate and efficient data integration.
Outcome:
To address this, EOS developed METL (Message ETL), an ETL streaming pipeline leveraging a Dynamic Mapping Matrix (DMM). This innovative approach automates updates in response to schema changes which facilitates parallel computation in near real-time and ensures efficient data compaction. By implementing METL, EOS achieved seamless integration of data across their microservices which enhanced the performance and reliability of their data-driven applications.
Key Takeaways
Adaptive Solutions for Dynamic Environments:
EOS's development of the METL pipeline underscores the necessity of adaptive solutions to manage the complexities inherent in modern microservice architectures. Organizations must create systems that can evolve with changing data structures.
Dynamic Mapping for Efficient ETL:
The introduction of a Dynamic Mapping Matrix illustrates the effectiveness of dynamic mapping in modern ETL processes. This innovation enables automatic updates to data models, ensuring that integration remains accurate and efficient in a rapidly changing environment.
Real-Time Processing Capabilities:
The incorporation of near real-time processing capabilities into their data pipelines allows EOS to maintain up-to-date information across microservices, enhancing the reliability and responsiveness of data-driven applications.
Seamless Data Integration:
The implementation of METL resulted in improved integration across various data sources, highlighting the importance of cohesive data architecture for successful data pipelines. This integration enhances overall system performance and enables better insights for decision-making.
Overall, these case studies emphasized the importance of scalability, cost efficiency, adaptive solutions, and seamless integration in achieving engineering excellence in data pipelines. Organizations can leverage cloud technology and innovative approaches to optimize their data management processes which leads to improved insights and operational efficiency.
Future Trends in Data Pipeline Engineering
- AI-Driven Pipelines: Look forward to the use of AI to automate pipeline optimization and anomaly detection, enhancing agility.
- Serverless Architectures: Explore serverless technologies that reduce operational overhead.
- Data Mesh: Understand the decentralization of data ownership and its impact on pipeline management.
- Sustainability: Focus on building energy-efficient data pipelines to contribute to overall sustainability goals.
Conclusion
Engineering excellence in data pipelines is crucial for organizations seeking to harness the potential of their data. By adopting best practices, leveraging modern tools, and learning from real-world examples, organizations can build pipelines that are not only scalable and reliable but also efficient and secure. As the landscape of data engineering continues to evolve, staying ahead of trends will ensure your organization remains competitive and innovative.
Resource
Please click HERE to download the checklist to achieve excellence in Data Pipelines. This checklist needs to be iteratively followed using instructions provided.
The article is also available here.

{kind=link}
{kind=link}